Kubernetes EFK
Kubernetes EFK
EFK Stack이란?
EFK(Elasticsearch, Fluentd and Kibana): Kubernetes 로그 집계 및 분석을 위한 인기 있는 최고의 오픈 소스입니다.
1. Elasticsearch
- 일반적으로 사용되는 확장 가능한 분산 검색 엔진으로써 대량의 로그 데이터를 선별
- Lucene 검색 엔진(Apache의 검색 라이브러리)을 기반으로 하는 NoSQL 데이터 베이스
- 로그를 저장하고 fluentd에서 로그를 검색
2. Fluentd
Kubernetes의 경우 Fluentd가 추가 구성 없이 컨테이너 로그를 구문 분석할 수 있습니다.
- Fluentd is a log shipper
- 다중 데이터 소스 및 출력 형식을 지원하는 오픈 소스 유형의 로그 수집 에이전트
- 또한 Stackdriver, Cloudwatch, elasticsearch, Splunk, Bigquery 등과 같은 솔류션으로 로그를 전달
- 로그 데이터를 생성하는 시스템과 로그 데이터를 저장하는 시스템 간의 통합 계층
3. Kibana
Elasticsearch는 방대한 양의 비정형 데이터를 분리하는 문제를 해결하는데 도움이 되며 많은 조직에서 사용되고 있습니다. Elasticsearch는 일반적으로 Kibana와 함께 배포됩니다.
- 쿼리, 데이터 시각화 및 대시보드를 위한 UI 도구
- 웹 인터페이스를 통해 로그 데이터를 탐색하고, 이벤트 로그에 대한 시각화를 구축
- 문제를 감지하기 위해 정보를 필터링하는 쿼리별 쿼리 엔진
- Kibana를 사용하여 모든 유형의 대시보드를 가상으로 구축 가능
- KQL(Kibana Query Language)은 Elasticsearch 데이터를 쿼리하는데 사용
EFK 아키텍처
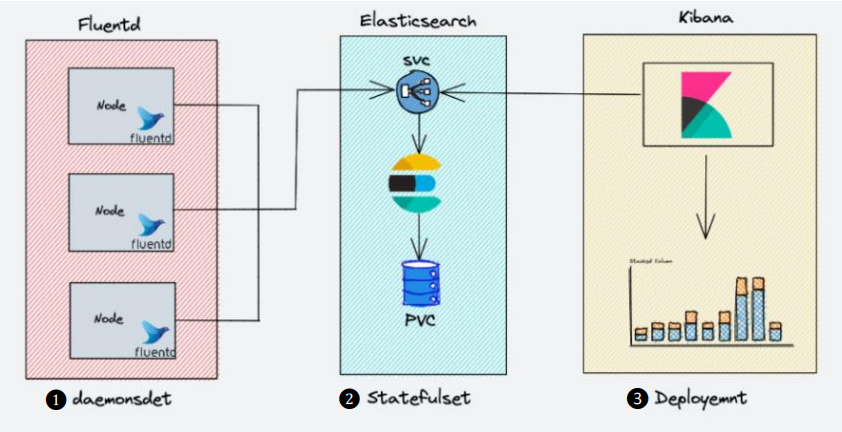
- 모든 노드에서 컨테이너 로그를 수집해야 하므로 daemonset으로 배포 Elasticsearch 서비스 엔드포인트에 연결하여 로그를 전달
- 로그 데이터를 보유하고 있으므로 statefulset로 배포 Fluentd 및 Kibana에 연결할 서비스 엔드포인트 노출
- Deployment로 배포되고 elasticsearch 서비스 엔드포인트에 연결
1
git clone https://github.com/scriptcamp/kubernetes-efk
EFK 실습
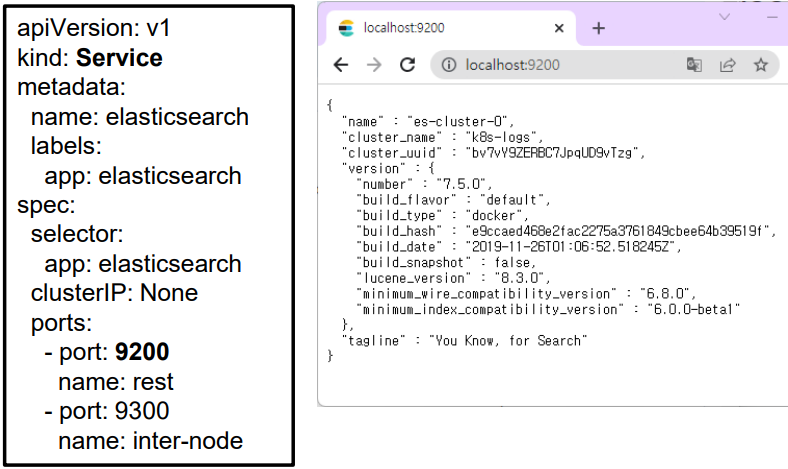
Deploy Elasticsearch Service
💡 elasticsearch 검색을 위한 서비스 생성
1
kubectl create -f es-svc.yaml
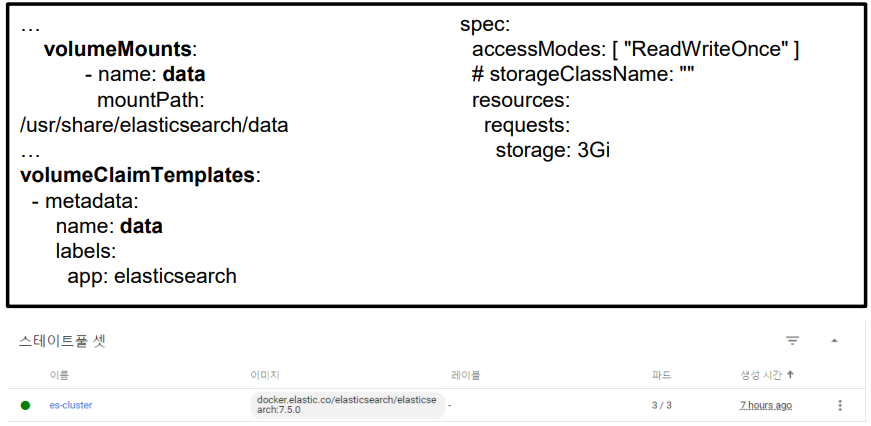
Deploy Elasticsearch Statefulset
- elasticsearch 검색을 위한 statefulset 생성을 시작하기 전에 statefulset 에는 필요할 때마다 볼륨을 생성할 수 있는 사전 정의된 스토리지 클래스가 필요합니다.
- 프로덕션 환경에서는 400~500Gbs이 필요하지만 여기서는 3Gb PVC를 사용하여 배포합니다.
- PVC (Persistance Volumn Claim)은 PV로 볼륨을 요청하고 바인딩하여 할당합니다.
1
kubectl create -f es-sts.yaml
Deploy Kibana Deployment
- Kubernetes deployment로 Kibana 를 생성할 수 있습니다. 그리고, Kibana 배포 매니페스트 파일을 확인하면 Elasticsearch 클러스터 엔드포인트를 구성하기 위해 env var ELASTICSEARCH_URL 이 정의되어 있습니다.
- Kibana는 엔드포인트 URL을 사용하여 Elasticsearch에 연결합니다.
1
kubectl create -f kibana-deployment.yaml

Deploy Kibana Service
1
kubectl create -f kibana-svc.yaml

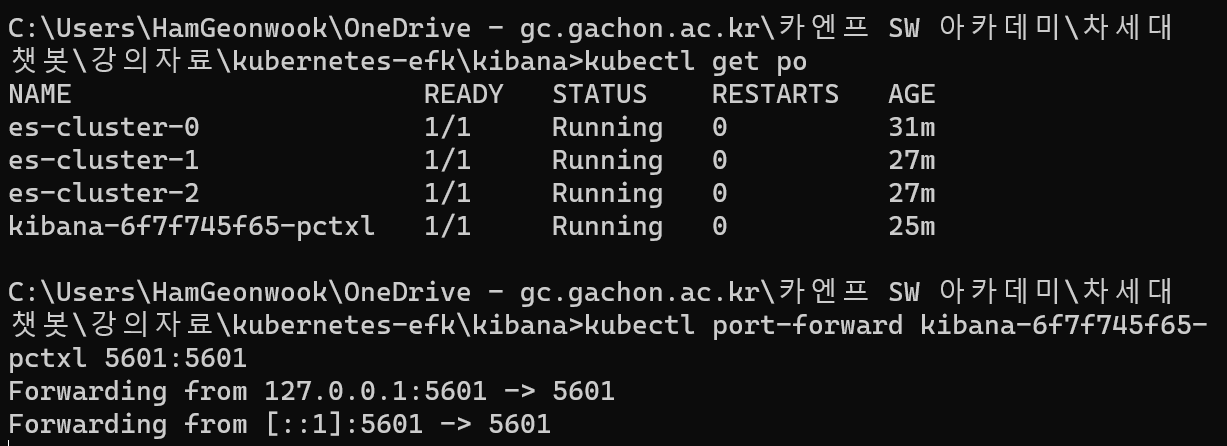
- kubectl get pods를 실행하고 kibana 파드이름으로 포트 포워딩을 합니다.
1
2
> kubectl get pods
> kubectl port-forward kibana-7bf5f786b9-q48v5 5601:5601
Create Fluentd Cluster Role
- kubernetes의 클러스터 역할에는 Cluster role을 나타내는 규칙이 포함되어 있습니다.
- fluentd의 경우 포드 및 네임스페이스에 대한 권한을 부여해야 합니다.
1
kubectl create -f fluentd-role.yaml

Create Fluentd Service Account
- kubernetes 에서 서비스 계정은 파드에 아이덴티티를 제공하는 엔티티입니다.
- 여기서는 **fluentd 포드와 함께 사용할 서비스 계정을 생성**하려고 합니다.
1
kubectl create -f fluentd-sa.yaml

Create Fluentd Cluster Role Binding
- kubernetes의 ClusterRole은 클러스터 역할에 정의된 권한을 서비스 계정에 부여합니다.
- 생성된 역할(fluentd)과 서비스 계정(fluentd) 간에 역할 결합을 생성합니다.
1
kubectl create -f fluentd-rb.yaml

Deploy Fluentd DaemonSet
- fluentd 데몬 셋을 생성합니다.
- dashboard에서 데몬 셋 생성을 확인합니다.
1
kubectl create -f fluentd-ds.yaml

fluentd-ds.yaml

- “FLUENT_ELASTICSEARCH_HOST” 및 “FLUENT_ELASTICSEARCH_PORT” 라는 두 가지 환경 변수를 사용
- Fluentd는 이러한 Elasticsearch 값을 사용하여 수집된 로그를 전달합니다.
Verify Fluentd Setup
- fluentd 설치를 확인하기 위해 지속적으로 로그를 생성하는 테스트 포드를 시작
- 그런 다음 Kibana 내부에서 이러한 로그를 확인
1
kubectl create -f test-pod.yaml

Kibana 연동
1
kubectl port-forward service/kibana-np 5601:8080
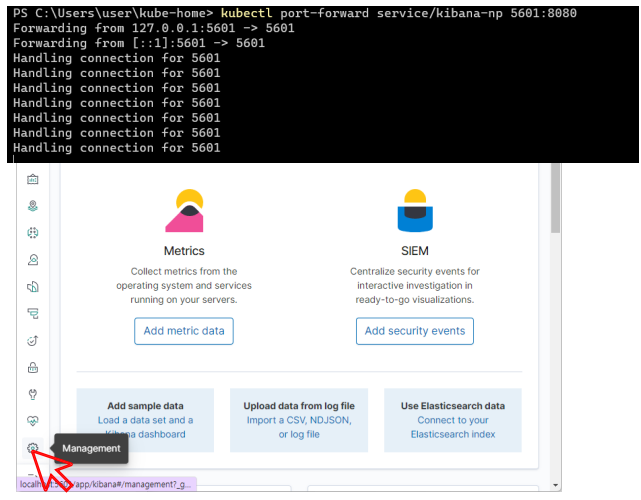
- Create index pattern을 클릭하여 로그 패턴을 생성합니다.
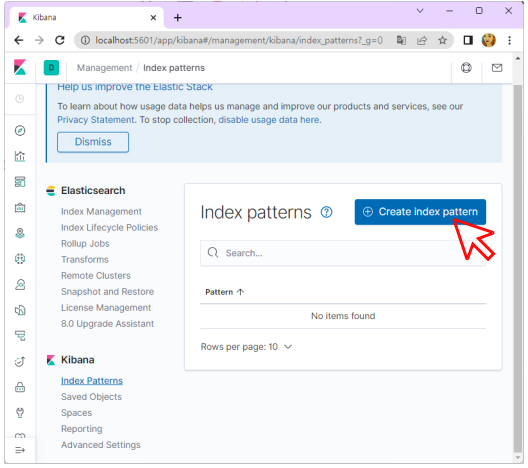
- “logstash-*” 패턴을 사용하여 새 인덱스 패턴 생성
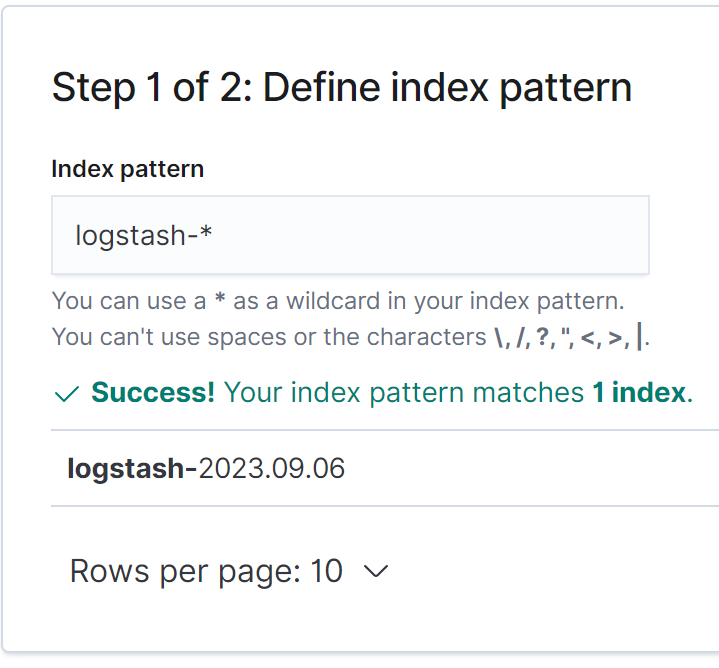
- @timestamp를 선택하고 Create index pattern 버튼 클릭
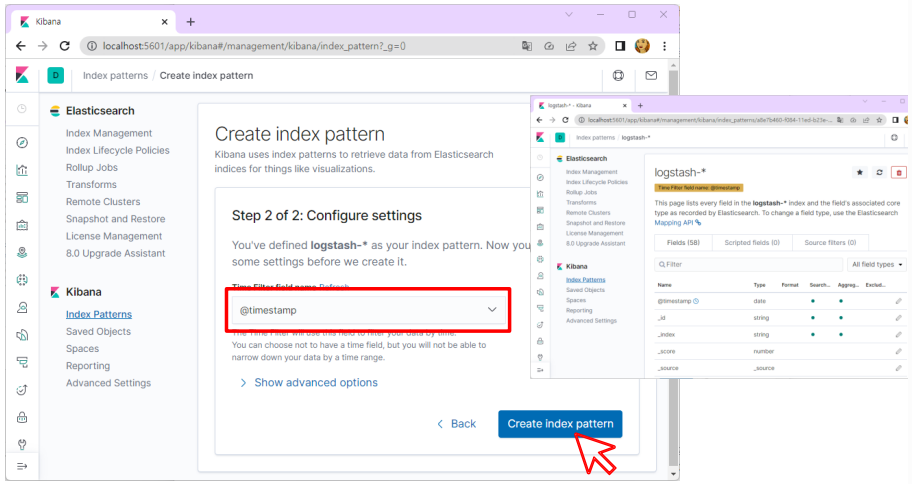
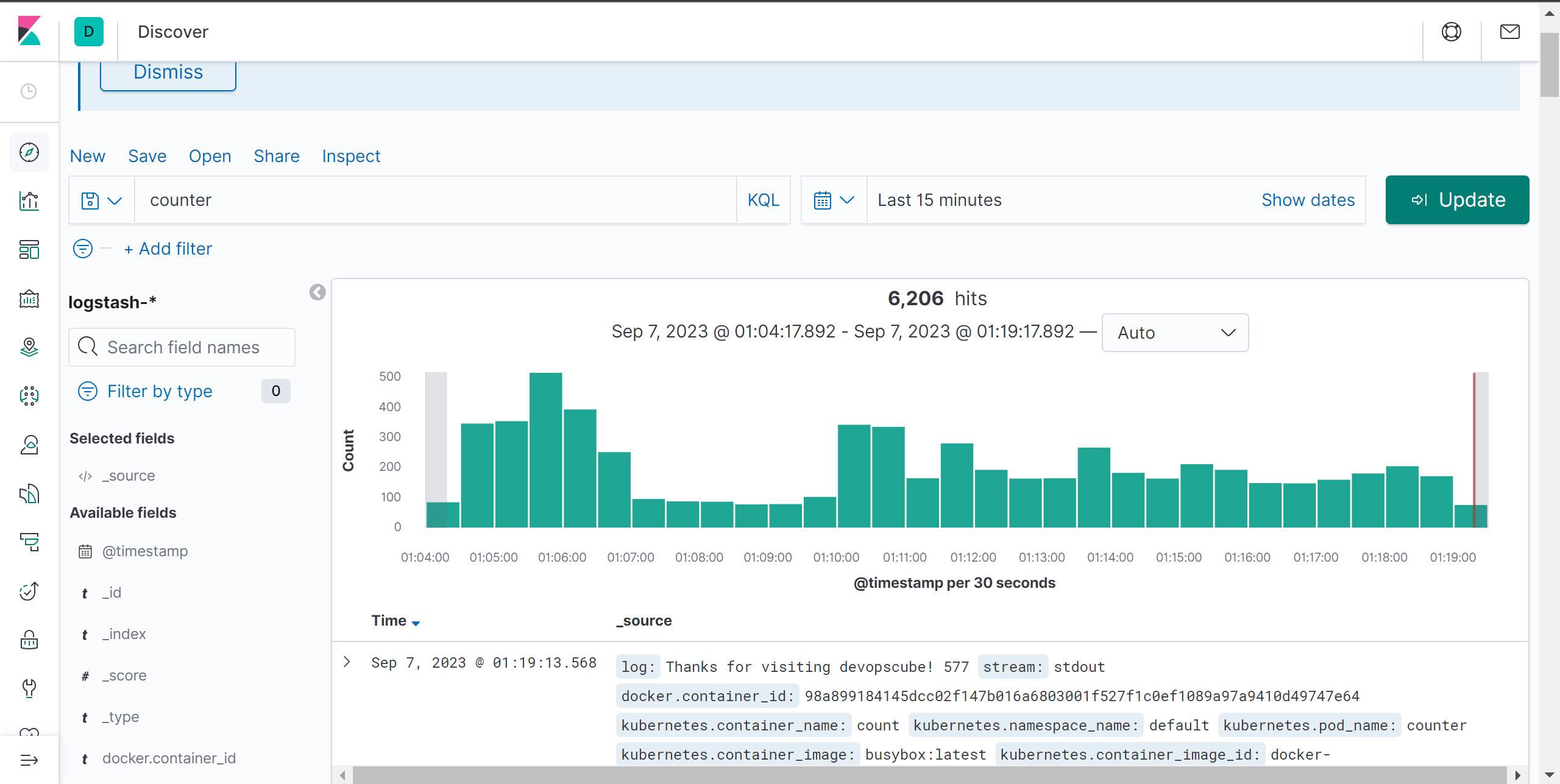
- Fluentd에서 내보내는 모든 로그를 볼 수 있습니다.
- counter 파드의 로그 확인
This post is licensed under CC BY 4.0 by the author.